




Déroulement de l'algorithme▲
Considérons un dataset comme celui-ci :
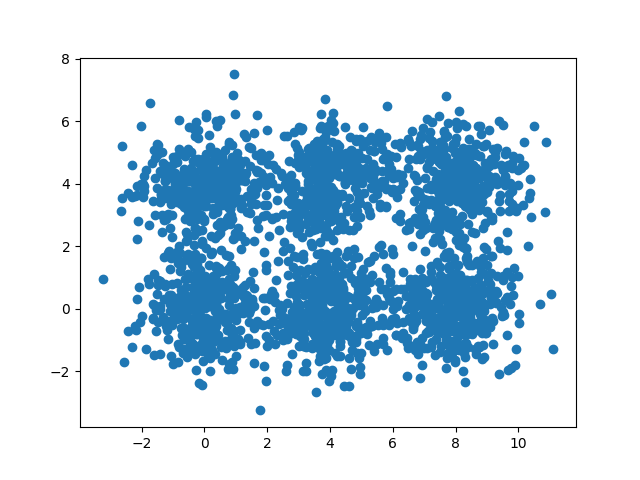
Nous pouvons visuellement remarquer qu'il y a six paquets de points. La convergence de l'algorithme sera la séparation des points en ces six paquets.
C'est un algorithme itératif qui va affiner sa solution à chaque étape. L'algorithme va déplacer itérativement k centres de paquets (appelés centroïdes) pour les rapprocher des points dont ils sont les plus proches.
Étapes de l'algorithme :
- positionnement des k centroïdes ;
-
pour chaque itération
- associer chaque point du dataset au centroïde le plus proche,
- déplacer les k centroïdes vers les barycentres des points dont ils sont les plus proches.
L'algorithme s'arrête lorsqu'on a atteint le nombre maximum d'itérations ou lorsque les centroïdes ne bougent plus.
Initialisation des centroïdes▲
Il y a plusieurs stratégies pour placer les centroïdes au début de l'algorithme :
- vous pouvez les placer aléatoirement dans la zone couverte par votre dataset ;
- vous pouvez considérer des éléments de votre dataset régulièrement espacés ;
- vous pouvez choisir de les placer volontairement en dehors du dataset.
Cependant, attention, le résultat de l'algorithme est influencé par les positions initiales des centroïdes. Ce sera visible dans les illustrations plus loin dans cet article.
Itérations de l'algorithme▲
La notion de proximité entre un point et un centroïde est laissée à votre appréciation. Dans le cas d'un dataset géométrique dans le plan, la notion de proximité peut être implémentée par la distance euclidienne.
De manière plus générale, la distance entre deux points a et b peut s'exprimer en n dimensions pour sommer les carrés des écarts sur chaque dimension.
kitxmlcodelatexdvpdistance(a,b) = \sqrt{\sum_{i=1}^n (a_i - b_i)^2}finkitxmlcodelatexdvpChaque point va être associé au centroïde dont il est le plus proche, puis le centroïde va se déplacer vers le barycentre de ces points.
2.
3.
4.
5.
6.
7.
for p in range(nb_points):
# on calcule la distance du point p à chaque centroïde
distances = [ distance( dataset[p] , c) for c in centroids]
# quel est le centroïde le plus proche ?
idCentroideProche = np.argmin(distances)
# on place le point p dans la liste des points associés à chaque centroïde
centroidesLesPlusProches[idCentroideProche].append(dataset[p])
Le déplacement d'un centroïde se fait en calculant la moyenne des points selon chaque caractéristique (ici x et y)
2.
3.
4.
5.
6.
7.
8.
for c in range(nb_centroids):
meanx = np.mean([centroidesLesPlusProches[c][p][0] for p in range(len(centroidesLesPlusProches[c])-1)])
meany = np.mean([centroidesLesPlusProches[c][p][1] for p in range(len(centroidesLesPlusProches[c])-1)])
# si meanx et meany ne changent pas, l'algorithme a convergé et on peut arrêter l'itération
centroids[c][0] = meanx
centroids[c][1] = meany
Convergence▲
Selon les positions de départ de nos centroïdes, nous pouvons obtenir plusieurs convergences différentes :
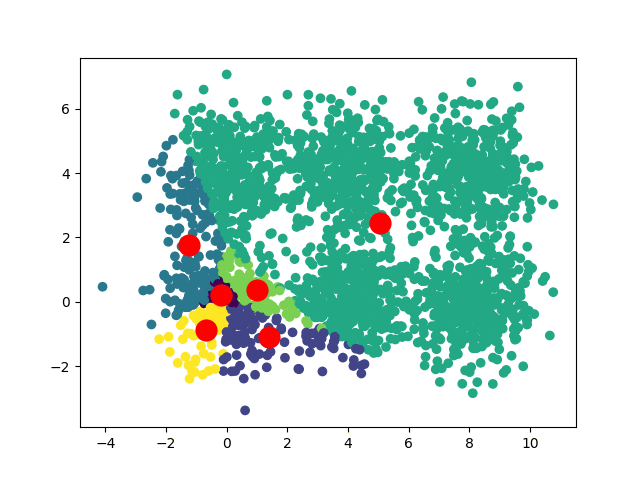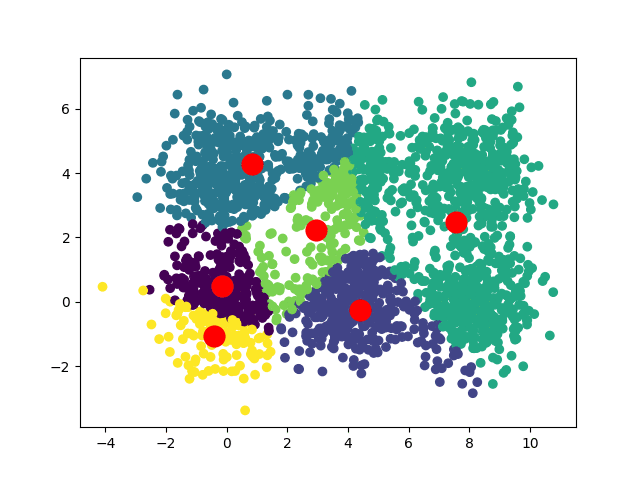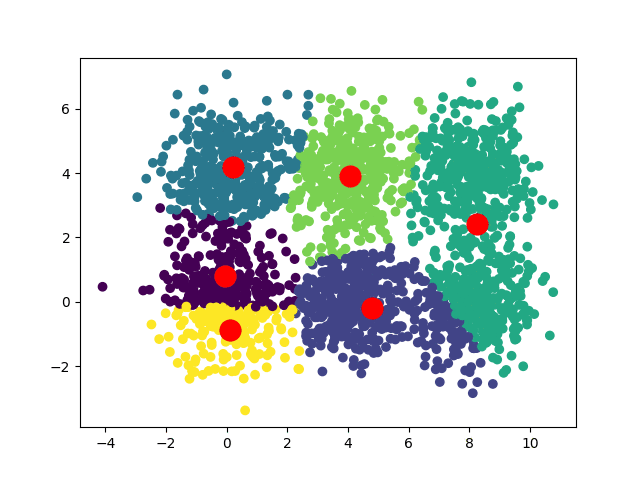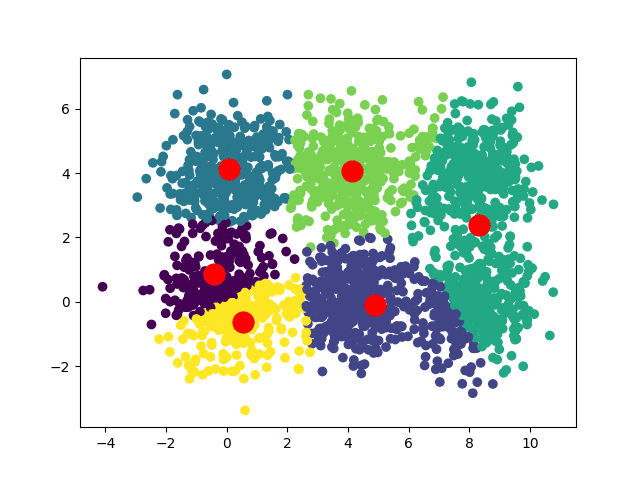
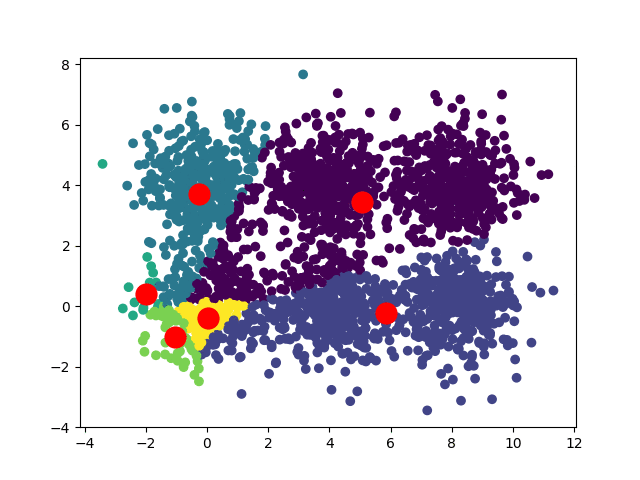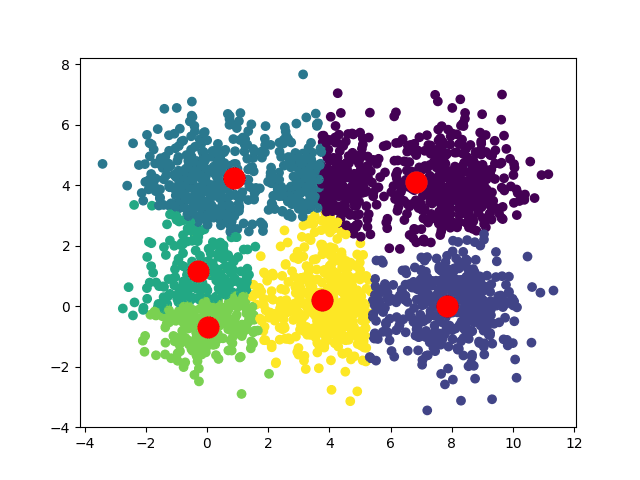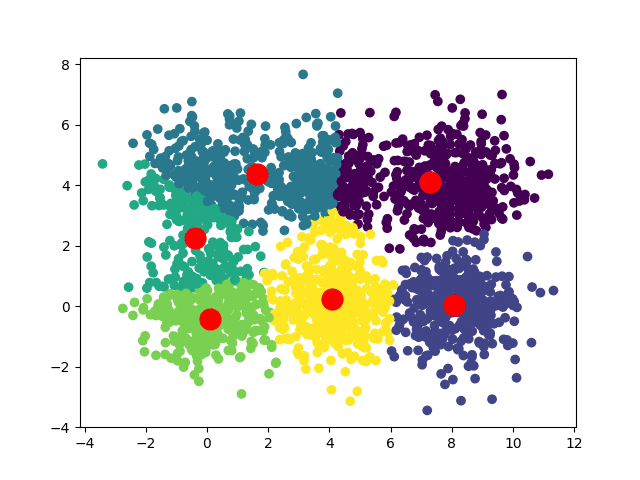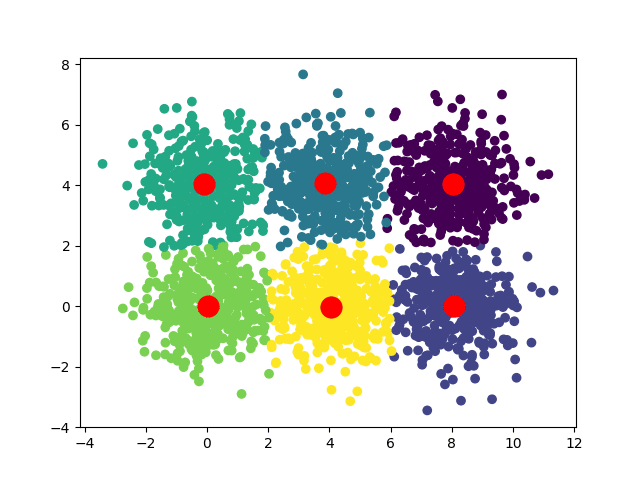
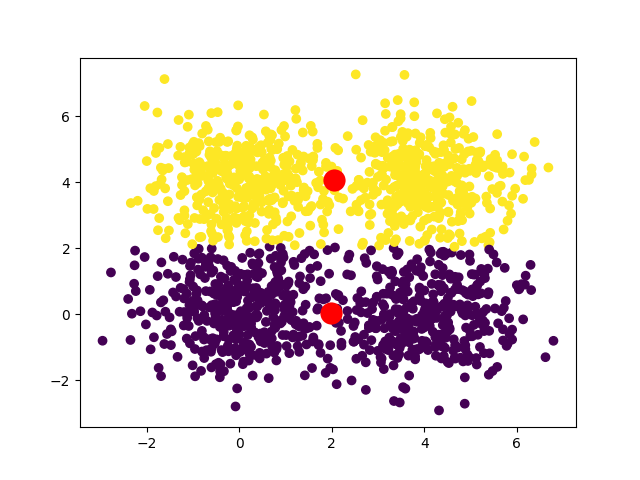
Dans le cas d'un dataset carré, on peut avoir deux convergences :
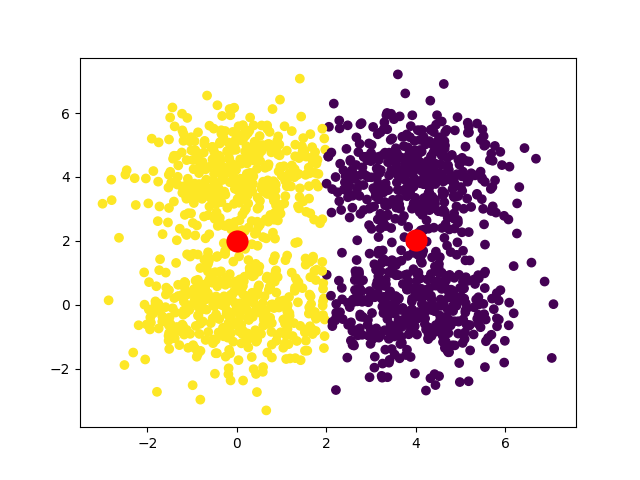
Si on souhaite obtenir une convergence unique (ou préférée), une solution intéressante est d'exécuter l'algorithme plusieurs fois, en prenant à chaque fois des centroïdes initiaux différents et de repérer quels résultats reviennent le plus souvent.
Combien de clusters repérer ?▲
À l'origine l'algorithme a été écrit pour qu'il donne les k centroïdes en connaissant k. Cependant on ne connaît pas toujours ce nombre k puisqu'il dépend de la forme qu'on cherche justement à analyser.
Voilà les convergences observées pour k=3, k=4, k=5 et k=8
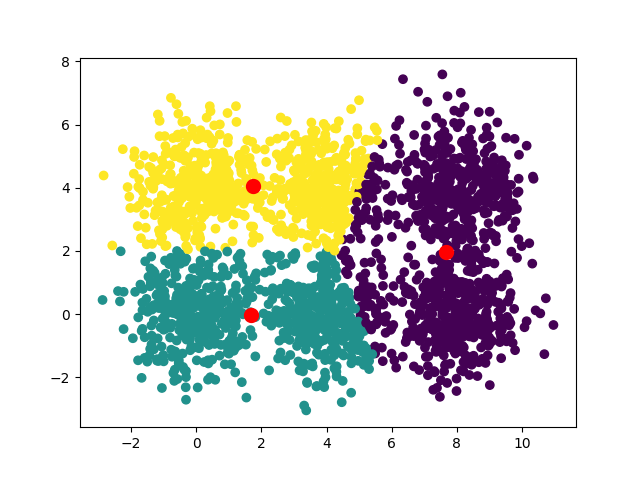
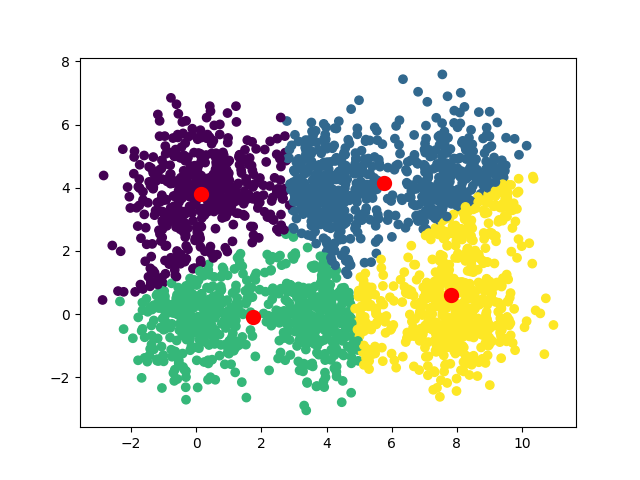
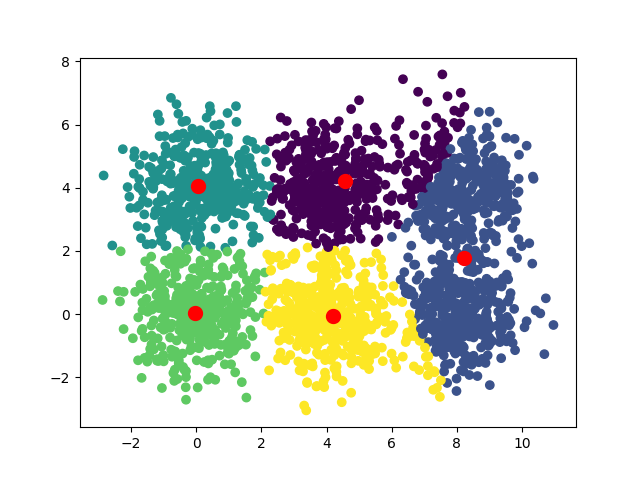
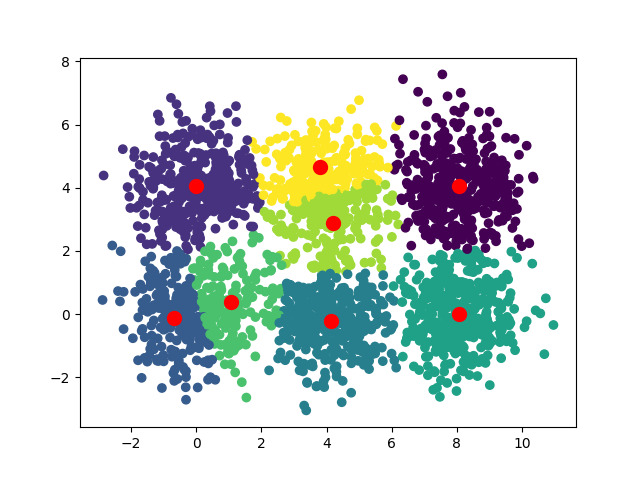
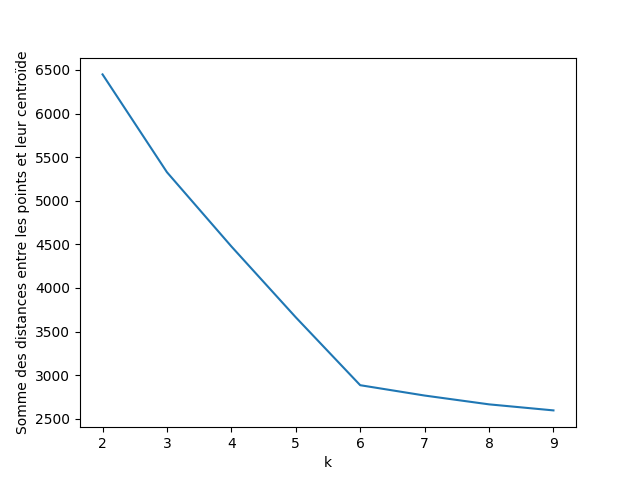
Une des idées intéressantes est d'exécuter l'algorithme avec différentes valeurs de k et de mesurer pour chacune la somme des distances entre les points et leur centroïde. En utilisant la technique du coude, vous pouvez mettre en évidence une valeur de k optimale. Dans notre cas la valeur optimale est 6, c'est là que le graphique fait un “coude”.
En conclusion▲
En conclusion, nous pouvons apprécier cet algorithme pour sa simplicité d'utilisation et de compréhension. Il dépend fortement des positions initiales des centroïdes et il dépend fortement de la fonction de distance que vous utilisez. Dans notre exemple nous avons recherché des clusters convexes (qui se ressemblaient au sens de la distance euclidienne). Si vous avez des ensembles allongés, l'algorithme des k-moyennes ne vous donnera pas forcément de bons résultats. Vos clusters doivent être linéairement séparables pour que l'algorithme des k-moyennes s'avère pertinent.
Si vous avez une idée de la forme de vos clusters, vous pouvez essayer de les retravailler en amont pour les rendre davantage convexes sinon vous devrez utiliser d'autres algorithmes de partitionnement de données.
Et bien sûr, cet algorithme a été implémenté dans les principales bibliothèques de manipulation de données. Ne vous embêtez pas à l'écrire à la main : il est ici.