




I. TensorFlow et la classification d'images▲
TensorFlow est un framework d'apprentissage automatique (Machine learning) développé par Google. Il est utilisable principalement en C++ et en Python, mais des portages sont disponibles pour la majorité des langages. Vous devez posséder Python 3.5+ pour bénéficier de TensorFlow 2 en Python.
L'installation se fait en utilisant votre gestionnaire de dépendance :
pip install tensorflowUne fois installé, le framework est accessible par un simple :
import tensorflow as tfTensorFlow intègre la bibliothèque Keras dédiée aux réseaux de neurones, c'est elle que nous allons utiliser pour développer un classifieur d'images.
L'une des premières utilisations des réseaux de neurones est la classification d'éléments. En fournissant un grand nombre d'éléments classifiés, le réseau va apprendre ce qui permet de différencier chaque classe d'éléments.
Je vais créer un réseau de neurones et lui faire apprendre un grand nombre d'images représentant des nombres. Chaque image de l'ensemble d'apprentissage est associée à la classe le représentant (les 10 nombres de 0 à 9). Je vais utiliser la bibliothèque d'images MNIST pour entraîner le réseau. Cette bibliothèque contient des milliers d'images 28x28 en niveau de gris. Voici quelques exemples des images d'apprentissage :

L'objectif du projet est de créer un réseau capable de comprendre quelques images créées manuellement. Vous pouvez également évaluer la qualité de votre réseau en utilisant les données MNIST de test, pour repérer le pourcentage de prédictions correctes après apprentissage.
II. Architecture du réseau▲
En entrée le réseau prend 28x28=784 pixels dont la luminosité varie entre 0 et 1.
En sortie le réseau indique les 10 classes existantes avec un niveau de confiance entre 0 et 1. On pourra naturellement supposer que la classe avec le meilleur score sera la classe prédite par le réseau.
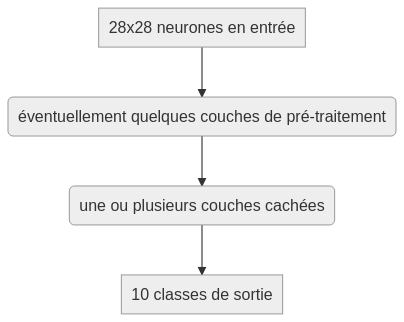
Le nombre et la taille des couches cachées restent encore aujourd'hui à l'appréciation du développeur et sont fortement dépendants du problème étudié. Il faudra faire plusieurs essais et corriger leurs performances respectives pour déterminer la meilleure architecture. Avec trop peu de neurones cachés, le réseau risque de ne pas être convergent et avec trop de neurones cachés, vous risquez le surapprentissage.
Le surapprentissage est un état où le réseau a parfaitement réussi à assimiler l'intégralité des données d'apprentissage, où il n'a pas eu besoin de chercher réellement ce qui différenciait chaque classe. Il avait suffisamment de neurones pour faire un apprentissage “par cœur” sans comprendre profondément chaque classe, sans avoir à se pencher en détail sur les différences entre chaque classe. En soumettant ensuite une image inconnue, le réseau aura du mal à la classifier correctement.
II-A. Création du réseau▲
La classe Sequential permet de définir l'enchaînement des couches du réseau. Keras propose plusieurs types de couches de neurones et chacune est paramétrable.
Flatten correspond à une couche où les neurones sont agencés en une liste linéaire. Elle permet de créer une couche d'entrée ou bien d'aplanir une couche sortant des données à plusieurs dimensions.
Dense correspond à une couche entièrement connectée à la couche précédente.
2.
3.
4.
5.
6.
7.
8.
9.
10.
model = tf.keras.models.Sequential([# première couche pour recevoir tous les pixels en entrée
tf.keras.layers.Flatten(input_shape=(28, 28)),
...
# définition de toutes les couches cachées
...
# dernière couche de 10 neurones, entièrement connectée à la couche précédente
tf.keras.layers.Dense(10),
# traitement pour ramener toutes les valeurs entre 0 et 1
tf.keras.layers.Softmax()
])
Une fois créé, le réseau doit être entraîné. Prenons les données MNIST. Keras propose les données directement exploitables, sous la forme d'une suite d'images en entrée (x) avec pour chacune la classe associé (y).
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()Ensuite le réseau va adapter ses poids pour faire correspondre toutes les entrées x aux sorties y. Le nombre d'itérations (et donc de raffinements) est noté epochs
model.fit(x_train, y_train, epochs=5)
Une fois le réseau entraîné, vous pouvez lui proposer des images et apprécier la prédiction :
II-B. Première version : couches cachées▲

Le code du réseau est le suivant :
2.
3.
4.
5.
6.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
])
On notera qu'on peut définir quelle fonction d'activation utiliser (sigmoid, linear, relu, tanh…). La doc est votre amie.
Voici la courbe d'apprentissage du réseau sur 50 générations :
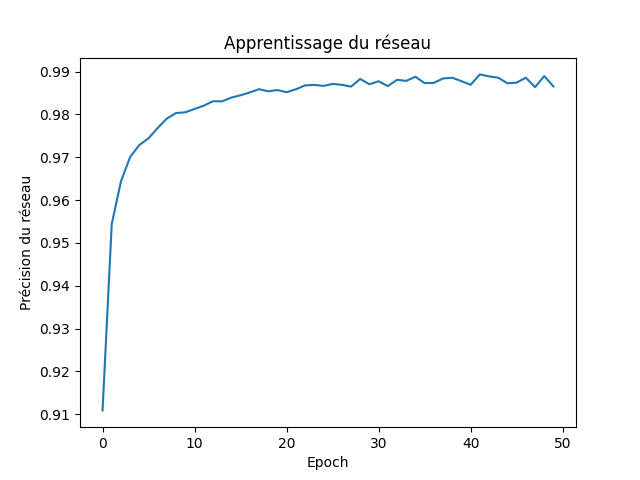
Attention, la précision de 99 % signifie que le réseau a réussi à ingérer les données d'apprentissage, pas qu'il sera capable de généraliser de prédire correctement sur des images inconnues.
J'ai généré plusieurs réseaux en augmentant le nombre de neurones, j'ai pu remarquer une amélioration de la prédiction en augmentant le nombre de neurones cachés, mais ce raisonnement peut mener au surapprentissage.
Voici une animation du résultat des prédictions pour l'utilisation de deux couches cachées allant de 100x100 neurones à plus de 7000x7000. On remarque que l'amélioration des prédictions n'est pas continue. Au bout d'un moment, il y a tellement de neurones que le réseau n'a pas besoin de tous les utiliser pour ingérer les données d'apprentissage. Les prédictions deviennent farfelues, c'est le surapprentissage.
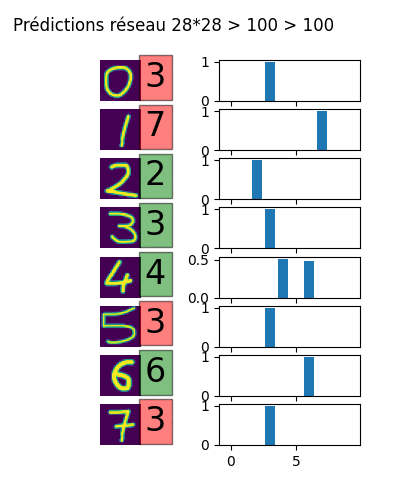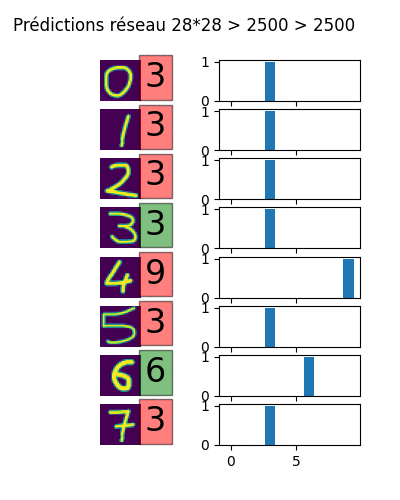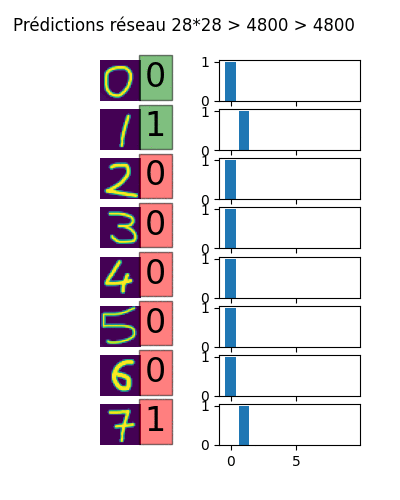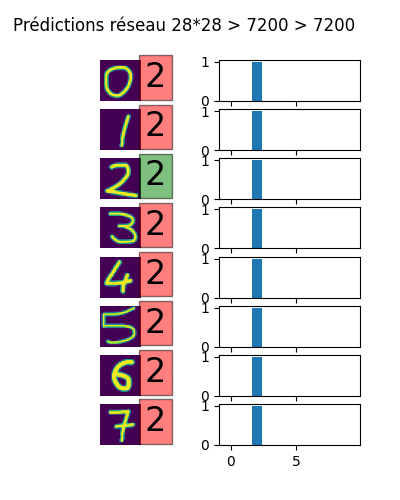
II-C. Couches de convolution▲
L'un des inconvénients des réseaux précédents est que la proximité des pixels n'est pas prise en compte. Une forme est constituée nécessairement de plusieurs pixels et leur enchaînement doit être pris en compte.
En passant des filtres de convolution sur l'image, nous allons pouvoir repérer des caractéristiques graphiques qui vont représenter les pixels alentour. Le réseau pourra se servir de ces données pour comprendre le voisinage et affiner les prédictions. Les résultats des convolutions sont appelés les “cartes de caractéristiques” (feature maps) et selon le filtre que vous appliquez, vous allez pouvoir repérer telle ou telle caractéristique sur votre voisinage.
Il est possible de repérer des contours orientés, des zones de fort gradient, des zones de faible gradient…
En enchaînant des couches de convolution, on va pouvoir repérer des éléments de plus en plus grands, pouvant potentiellement se rapprocher des objets à classifier. Le nombre de couches de convolution est directement lié à la taille de l'image à analyser. Vous aurez besoin de beaucoup plus de couches de convolution pour repérer des objets de plusieurs centaines ou milliers de pixels. Les couches de convolution peuvent être vues comme un traitement préalable à l'utilisation des neurones. C'est un moyen d'améliorer les données en entrée pour mettre toutes les chances de notre côté pour obtenir une bonne prédiction en sortie du réseau.
Les filtres de convolution peuvent être générés aléatoirement, la caractéristique qu'ils repèrent n'est alors plus aussi évidente ni visuelle que si vous aviez choisi un filtre plus habituel (par exemple détection de contours). En générant 20 filtres, on obtiendra 20 cartes de caractéristiques, chacune repérant une caractéristique particulière.
Une rapide expérimentation vous montrera que la géométrie en sortie d'une convolution n'est pas celle qui était en entrée. Le bord de l'image peut être conservé ou ignoré. C'est le rôle du paramètre “padding”. En le plaçant à “SAME”, la géométrie sera conservée. TensorFlow rajoutera des valeurs 0 sur les bords, là où la convolution ne ramène aucune valeur.
En utilisant n cartes de caractéristiques, vous allez multiplier par n le nombre de données en entrée de votre réseau. L'une des stratégies est de diminuer la complexité du problème et donc de diminuer le volume de données pour se concentrer sur les données porteuses d'information, qui pourront guider la discrimination du classifieur.
II-C-1. MaxPool▲
Le MaxPool est un outil permettant de réduire la taille d'une carte de caractéristiques en réduisant un carré de pixels à un seul pixel, en prenant le pixel de plus grande valeur. En prenant un MaxPool 2x2, on va prendre un pixel pour chaque carré 2x2 et ainsi diminuer par 4 le nombre de pixels d'une couche du réseau.
L'usage est d'associer des couches MaxPool à des couches de convolution pour repérer les caractéristiques graphiques puis les réduire, quitte à régénérer des caractéristiques sur ces réductions. Une fois les données caractérisées et réduites, elles sont placées dans un réseau “classique”, pour prédire la classe de l'image d'entrée.
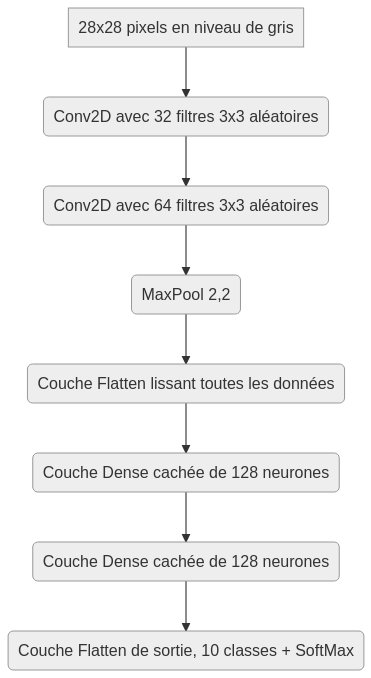
II-D. Conv2D + MaxPool + réseau 128x128▲
Voici le réseau que je propose de réaliser :
Voici la courbe d'apprentissage du réseau sur 50 générations :
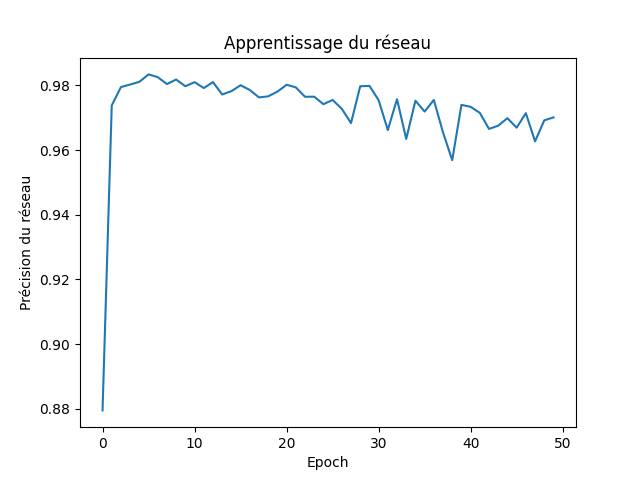
L'apprentissage peut sembler moins efficace que dans la première version, mais ce qui nous intéresse c'est la capacité du réseau à généraliser.
III. Pour aller plus loin▲
Vous pouvez continuer à améliorer les réseaux proposés ici pour augmenter la qualité des prédictions. Vous pouvez jouer sur la taille des filtres de convolution, sur leur nombre, sur l'enchaînement des couches de convolution et des couches de MaxPooling… Si votre matériel le permet, TensorFlow pourra utiliser CUDA et s'exécuter beaucoup plus rapidement que sur un simple CPU.
Le sujet des réseaux de neurones est un sujet de recherche très actif et de nombreuses avancées sont proposées chaque année. De nouveaux types de réseaux sont régulièrement proposés.