




Déroulement de l'algorithme▲
Considérons un dataset comme celui-ci :
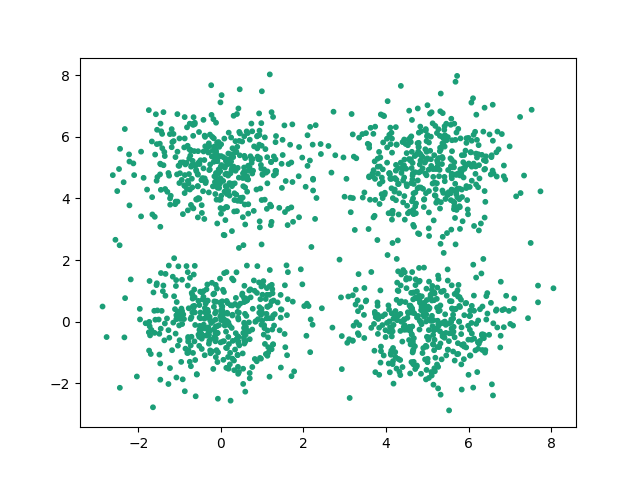
Nous pouvons observer quatre clusters principaux. La convergence de l'algorithme sera le repérage de ces quatre clusters. Les points alentours pourront être considérés comme du bruit à exclure des clusters selon les paramètres choisis pour notre algorithme.
C'est un algorithme itératif qui va repérer les points de proche en proche pour étendre les groupes de points aux points voisins. L'algorithme va suivre la forme des données et repérer toutes celles qui correspondent aux critères de proximité.
L'algorithme se base sur deux paramètres :
- la distance de voisinage kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp à considérer autour d'un point pour trouver d'autres points proches ;
- le nombre minimum de points proches (minPoints) qu'il faut avoir pour qu'un point soit dans un cluster.
L'algorithme va parcourir le dataset dans un ordre aléatoire et pour chaque point il va se poser les questions suivantes :
- le point courant a-t-il déjà été traité ? Si oui, on ne fait rien pour ce point ;
-
le point courant a-t-il assez de voisins proches pour commencer un nouveau cluster kitxmlcodeinlinelatexdvpC_ifinkitxmlcodeinlinelatexdvp ?
-
si oui
- on rattache le point courant au cluster kitxmlcodeinlinelatexdvpC_ifinkitxmlcodeinlinelatexdvp,
- on rattache les points voisins au cluster kitxmlcodeinlinelatexdvpC_ifinkitxmlcodeinlinelatexdvp,
- on cherche de proche en proche à partir de chaque point voisin si d'autres voisins sont eux aussi suffisamment nombreux.
-
De cette manière, l'algorithme va catégoriser chaque point :
- les points ne faisant partie d'aucun cluster (le bruit) ;
- les points faisant partie d'un cluster et qui ont assez de voisins (les points centraux) ;
- les points faisant partie du cluster, mais qui n'ont pas assez de points pour étendre encore le cluster (les points frontière).
Notion de distance▲
Comme pour l'algorithme des k-moyennes, la notion de distance est laissée à l'appréciation du concepteur. Dans un cas géométrique la distance peut intuitivement s'exprimer comme la norme euclidienne, mais il faut considérer que notre dataset peut représenter des données bien différentes, avec des dizaines de dimensions où seulement certaines sont à prendre en compte.
Notion de voisinage▲
Le voisinage représente l'ensemble des points du dataset dont la distance à un point p est inférieure au seuil kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp.
En prenant un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp grand, on prend le risque d'autoriser des sauts plus grands entre deux points du cluster. On pourra ainsi regrouper deux clusters qui n'auraient pas dû l'être.
En prenant un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp trop petit, on prend le risque que l'algorithme ne puisse repérer aucun cluster.
Pour des grands datasets et dans un souci d'efficacité, il est illusoire de chercher à comparer un point à l'ensemble du dataset pour savoir s'ils sont assez proches. L'utilisation d'un quad-tree (ou d'une structure similaire en dimension supérieure) permettra de réduire considérablement le temps de recherche des points voisins.
Une fois que la recherche de voisinage est optimisée, l'algorithme se résume à un simple parcours itératif des points du dataset.
Implémentation▲
Considérons un dataset à deux dimensions (x et y). J'adjoins à chaque point deux valeurs entières : une qui permettra de savoir si le point a déjà été traité ou pas et une autre qui repère le numéro de son cluster.
À l'initialisation, tous les points sont rattachés au cluster -1 (bruit) et aucun n'est traité.
dataset[:,2] = -1 # cluster n° -1
dataset[:,3] = 0 # non traitéLa boucle principale parcourt les points et cherche à commencer des nouveaux clusters :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
for i in range(len(dataset)):
# si le point n'a pas été parcouru
if dataset[i][3] == 0:
dataset[i][3] = 1 # on indique que maintenant le point est parcouru
pointsVoisins = prochesVoisins(i)
# si le point p a suffisamment de voisins, on crée un cluster
if len(pointsVoisins) >= minPoints:
clusterId = clusterId+1
dataset[i][2] = clusterId
etendreLeCluster(pointsVoisins, i, clusterId)
La fonction etendreLeCluster est chargée de trouver tous les points qui feront partie d'un cluster courant. Elle va explorer les points de proche en proche.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
def etendreLeCluster(voisins, p, clusterId):
i=0
while i < len(voisins):
idvoisin = voisins[i]
# si le point n'est pas encore traité, il le devient
if dataset[idvoisin][3] == 0:
dataset[idvoisin][3] = 1
# si le point n'était dans aucun cluster, il fait partie du cluster courant
if dataset[idvoisin][2] == -1:
dataset[idvoisin][2] = clusterId
# on recherche les voisins de chaque voisin
voisins2 = prochesVoisins(idvoisin)
if (len(voisins2) >= minPoints):
# on complète la liste des points à explorer avec les voisins des voisins
for p in voisins2:
if not np.isin(p, voisins):
voisins.append(p)
i = i+1
On repère l'intérêt du second paramètre de l'algorithme : minPoints. Ce paramètre permet de séparer les points légitimes du bruit. En prenant un minPoints important, on va obliger le cluster à être très dense. En prenant un minPoint faible, on va autoriser les clusters éparpillés et faiblement denses.
L'un des avantages de cet algorithme est qu'il n'a pas besoin de connaître a priori le nombre de clusters présents dans le dataset : il va tous les trouver. Il est également capable de repérer des clusters de taille et de forme arbitraires.
Animations et illustrations▲
Voici un exemple de résolution correcte avec minPoints = 6 et kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp = 0.3
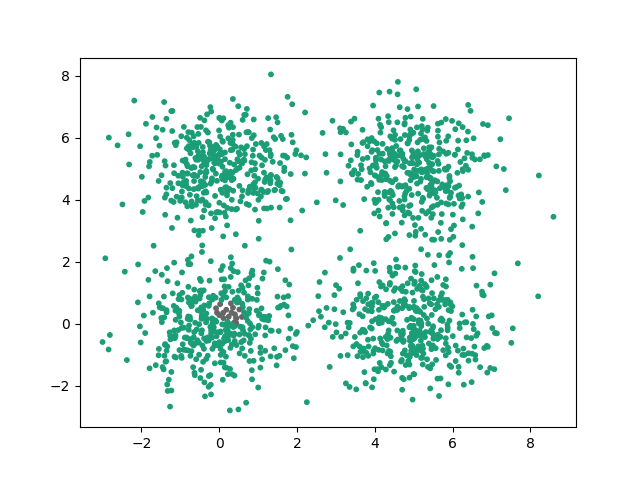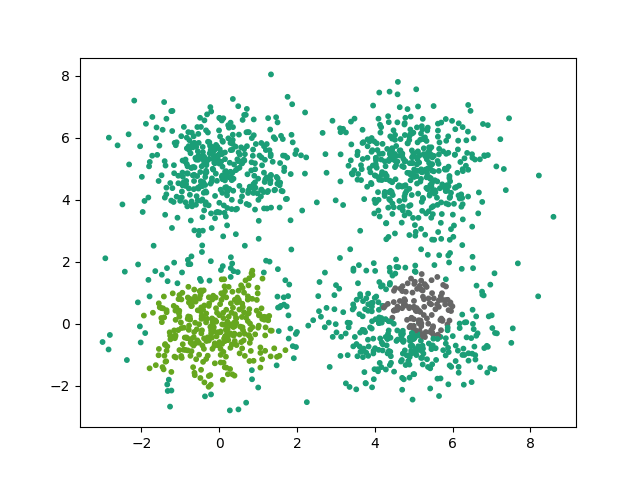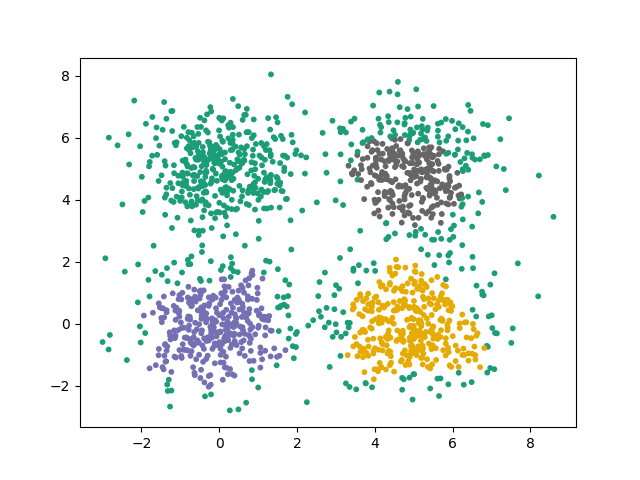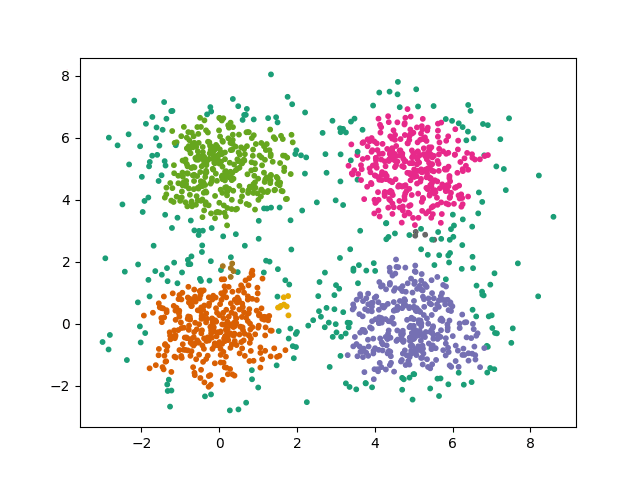
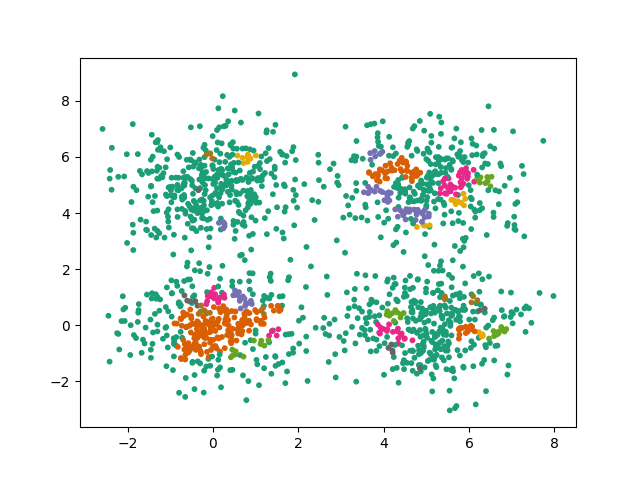
En prenant un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp faible, les clusters ne peuvent plus s'étendre correctement :
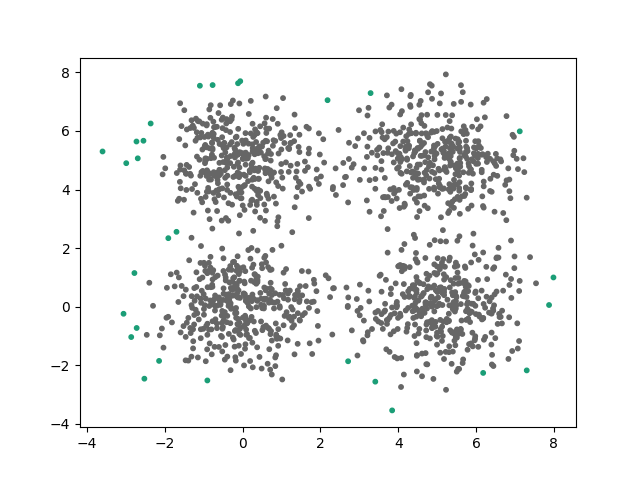
Avec un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp trop grand, le partitionnement est faux et du bruit est rajouté aux clusters repérés.
Qualité du partitionnement▲
Vous pouvez juger de la qualité de votre partitionnement en estimant la part de bruit encore présent à la fin de l'algorithme. Utilisez un histogramme par cluster pour visualiser la taille de chaque cluster.
Voici trois histogrammes pour un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp petit, correct et grand.
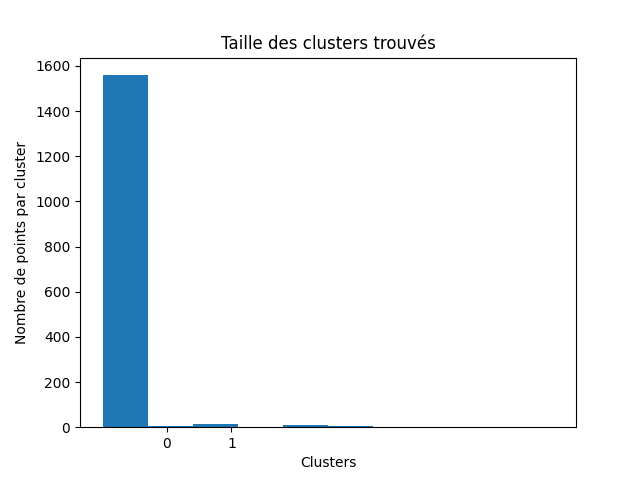
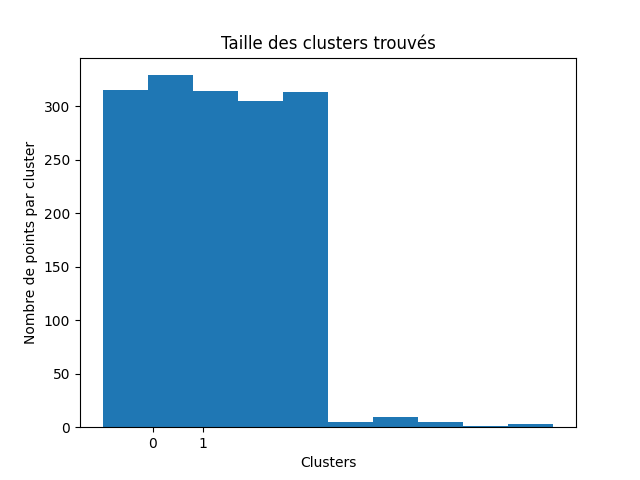
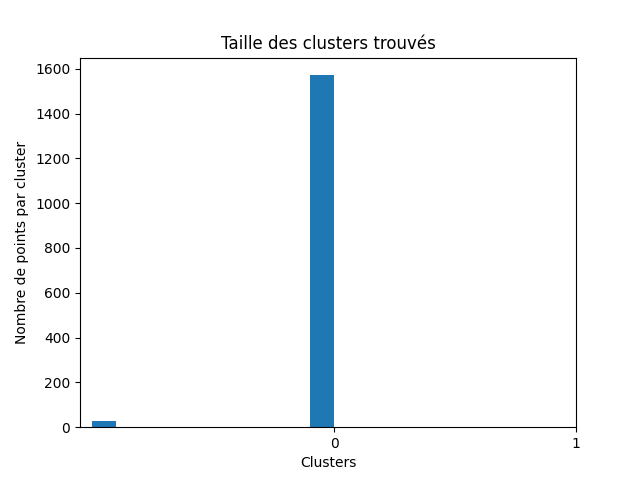
Le premier cluster est celui des points bruités. On remarque qu'avec un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp petit il n'y a quasiment que du bruit (95 %), les clusters n'ont pas pu s'étendre. Avec un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp grand, il n'y a quasiment plus de bruit, mais pas assez de clusters. Avec un kitxmlcodeinlinelatexdvp\epsilonfinkitxmlcodeinlinelatexdvp moins extrême, l'algorithme a pu trouver des vrais clusters (4) et il reste du bruit à hauteur de 20 % du dataset.
Si le taux de bruit observé correspond au bruit réel de votre dataset (que vous connaissez généralement), vous pouvez nettoyer votre dataset en l'enlevant. Attention cependant, rien ne vous prouve que le bruit repéré par l'algorithme correspond au bruit réel et exhaustif.
De la même manière, vous pouvez supprimer les petits clusters si vous connaissez le nombre ou la taille moyenne des clusters attendus. Dans notre exemple à quatre clusters + du bruit, il est possible de tout supprimer sauf les quatre clusters.
En conclusion▲
Vous pouvez apprécier cet algorithme pour sa capacité à évoluer sans connaître le nombre de clusters et pour sa capacité à repérer des clusters de tailles quelconques. Il permet de repérer des clusters non séparables linéairement. Il est également robuste au bruit. En cela, il corrige certains défauts de l'algorithme k-means.
Vous pouvez aussi vous en servir comme nettoyeur de dataset, pour fournir des données à un traitement ultérieur dans votre pipeline d'analyse de données.
Et bien sûr, ne vous amusez pas à le réécrire, il est là.