





Premiers pas▲
Scikit-learn s'installe comme la majorité des paquets Python :
pip3 install scikit-learnSi vous utilisez la distribution Anaconda, Scikit-learn est déjà installé.
Le dataset IRIS contient 150 observations de fleurs d'iris, avec pour chacune d'elles quatre caractéristiques (longueur et largeur des pétales, longueur et largeur des sépales) et le nom de la variété d'iris. Le cas d'usage habituel est de créer des modèles permettant de prédire la variété en fonction des caractéristiques observées. De cette manière, les caractéristiques sont considérées comme des features du dataset (habituellement notées X) et la variété est la target (l'élément à deviner, habituellement noté Y).
Ensembles d'entraînement, de test et de validation▲
Dès que vous souhaitez mettre en place un apprentissage automatisé, vous avez besoin de manipuler plusieurs ensembles. Vous allez découper votre ensemble labellisé en plusieurs sous-ensembles :
- un ensemble d'entraînement pour entraîner vos modèles de machine learning ;
- un ensemble de test pour mesurer la performance de vos modèles sur des données non apprises. La performance d'un modèle sur l'ensemble de test correspond à une mesure de ce modèle sur des données réelles, qui permettent d'évaluer la capacité de généralisation du modèle ;
- vous pouvez éventuellement utiliser un ensemble de validation pour déterminer les meilleurs hyper-paramètres de vos modèles. Vous allez ainsi rechercher le meilleur paramétrage de vos modèles sans pour autant vous servir de l'ensemble de test.
Il est nécessaire que tous les ensembles que vous manipulez soient représentatifs du cas à modéliser sans quoi vous allez tester le modèle sur des données qui ne correspondent pas aux données d'entraînement. C'est pourquoi vous devez vous assurer que les distributions de tous ces ensembles sont comparables. Généralement on réalise des coupes aléatoires dans le dataset pour déterminer les sous-ensembles.
Le découpage d'un dataset en ensemble d'entraînement et ensemble de test se fait par Scikit-learn :
2.
3.
4.
from sklearn.model_selection import train_test_split
# L'ensemble de test aura 20 % des éléments de départ.
# L'ensemble d'entrainement contiendra les 80 % restant.
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
Validation croisée▲
Le souci dans l'utilisation d'un ensemble de test c'est que vous allez réduire votre ensemble d'entraînement pour isoler un ensemble de test. Si votre jeu de données est restreint, vous allez le restreindre encore plus et cela pourra pénaliser l'apprentissage : avec trop peu de données, le modèle ne pourra pas apprendre correctement.
Un autre souci à l'utilisation d'un ensemble de test c'est qu'il est nécessairement plus petit et que les mesures de performances du modèle sur ce petit ensemble risquent de ne pas représenter sa capacité à généraliser. Un ensemble petit aura plus de mal à rester représentatif des données réelles.
C'est pourquoi on choisira souvent d'utiliser une validation croisée pour affiner les hyper-paramètres d'un modèle. La validation croisée consiste en une suite de découpages distincts en un ensemble d'entraînement et un ensemble de validation. Chaque découpage permet de mesurer une performance du modèle et la moyenne des performances de chaque découpage permet de trouver les meilleurs hyper-paramètres sans jamais avoir validé le modèle sur une donnée déjà apprise.
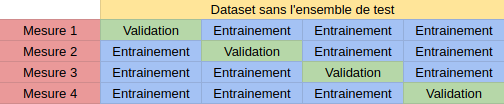
Scikit-learn implémente déjà ce mécanisme de découpages :
2.
3.
4.
from sklearn.model_selection import cross_val_score
model = ...
scores = cross_val_score(model, X, Y, cv=5) #cv est le nombre de découpages à réaliser
score = scores.mean()
Classification▲
Scikit-learn implémente de nombreux algorithmes de classification parmi lesquels :
- perceptron multicouches (réseau de neurones) sklearn.neural_network.MLPClassifier ;
- machines à vecteurs de support (SVM) sklearn.svm.SVC ;
- k plus proches voisins (KNN) sklearn.neighbors.KNeighborsClassifier ;
- …
Ces algorithmes ont la bonne idée de s'utiliser de la même manière, avec la même syntaxe. Vous pouvez ainsi aisément les interchanger, les remplacer et les comparer.
Le principe de Scikit-learn est à chaque fois le même :
- instanciation du modèle model = nom_du_modèle(liste des hyper-paramètres) ;
- entraînement du modèle sur les features X et les targets Y : model.fit(X, Y). À la fin de l'entraînement, le modèle est prêt à être utilisé pour prédire des targets ;
- utilisation du modèle pour prédire de nouvelles données : Y_predicted = model.predict(X_to_predict) ;
- mesure de l'efficacité du modèle : model.score(X_test, Y_réels). Cet appel va prédire des Y associés aux X d'entrée et les comparer aux Y_réels.
La classification KNN appliquée au dataset IRIS pourrait ressembler à ça :
2.
3.
4.
5.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 5)
model.fit(X_train, Y_train)
y_pred = model.predict(X_test)
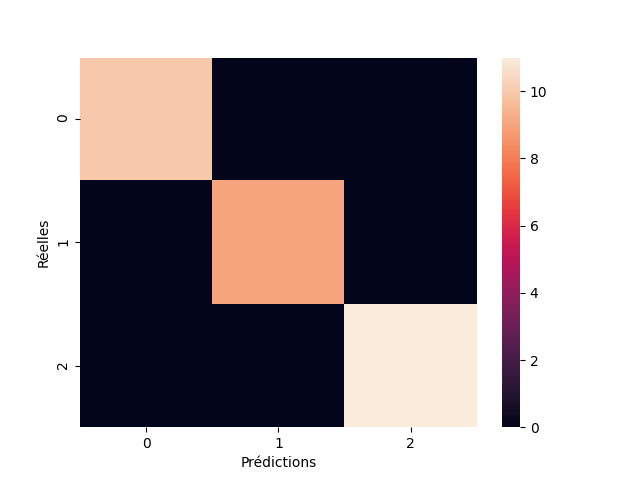
Par chance ce modèle KNN est parfaitement convergent sur ce petit dataset IRIS, mais ce n'est évidemment pas toujours le cas. La matrice de confusion est idéale : elle est diagonale, ce qui signifie que tous les éléments d'une classe ont été prédits dans la même classe.
Évidemment, chaque algorithme a ses propres hyper-paramètres. Il y a une valeur par défaut pour chacun, mais il est recommandé de connaître les principaux hyper-paramètres de chaque algorithme : le KNN demande de fournir le nombre de voisins k, le perceptron multicouches demande d'indiquer le nombre de couches et le nombre de neurones de chaque couche, le SVC demande le paramètre de régularisation C. La doc officielle de Scikit-learn vous donnera toutes les infos sur ces paramètres.
Bien que Scikit-learn propose un classificateur basé sur les réseaux de neurones, il n'est pas aussi évolué que celui proposé par Keras et repris dans TensorFlow.
Recherche des meilleurs hyper-paramètres▲
À part avec beaucoup d'intuition, il n'est pas possible de deviner les meilleurs hyper-paramètres pour un ensemble d'entraînement donné. Scikit-learn propose deux méthodes de recherche :
- GridSearchCV : qui va tester le modèle avec toutes les combinaisons d'hyper-paramètres, pour trouver les meilleures valeurs ;
- RandomizedSearchCV, qui va tester au hasard quelques combinaisons d'hyper-paramètres, pour trouver les meilleures.
Le principe est de définir un dictionnaire de paramètres et de valeurs à tester :
2.
3.
4.
from sklearn.model_selection import GridSearchCV
parameters = {"n_neighbors": [2,3,4,5]}
model = GridSearchCV(KNeighborsClassifier(), parameters)
model.fit(...)
Dans notre exemple, le GridSearchCV va tester le résultat sur les quatre valeurs de n_neighbors fournies. Pour les algorithmes possédant beaucoup d'hyper-paramètres avec beaucoup de possibilités pour chacun, la recherche exhaustive peut prendre du temps et il faudra trouver un meilleur moyen d'optimiser les hyper-paramètres : c'est l'intérêt de RandomizedSearchCV où seul un certain nombre de possibilités aléatoires est testé.
Notons au passage l'existence d'une troisième méthode de recherche de meilleurs hyper-paramètres, bien qu'elle ne soit pas officiellement intégrée à Scikit-learn : la recherche génétique. En réalisant des mutations et des croisements sur plusieurs combinaisons d'hyper-paramètres, l'algorithme génétique va essayer de se rapprocher de l'optimum sans explorer toutes les possibilités. Pour plus d'infos sur les algorithmes génétiques, je vous renvoie à mon article sur le sujet.
Il doit certainement y avoir encore d'autres méthodes de recherche et chacun pourra développer la sienne.
Régression▲
D'une manière générale, le mécanisme de régression permet d'exhiber une fonction mathématique s'approchant d'un ensemble de données. En étudiant une nouvelle donnée, on pourra la soumettre à la fonction et obtenir la prédiction du modèle. C'est un mécanisme qu'on peut qualifier de machine learning bien qu'il ne s'agisse pas d'associer une donnée à un ensemble fini de classes de sortie. Les valeurs de sortie sont infinies, mais le traitement se base néanmoins sur un apprentissage.
Scikit-learn propose plusieurs méthodes de régression, utilisant des propriétés statistiques des datasets ou jouant sur les métriques utilisées. Les méthodes principalement utilisées sont les régressions linéaires. Bien souvent une partie du préprocessing sera de rendre vos données linéaires, en les transformant. Une fois transformées vous pouvez utiliser les régressions proposées.
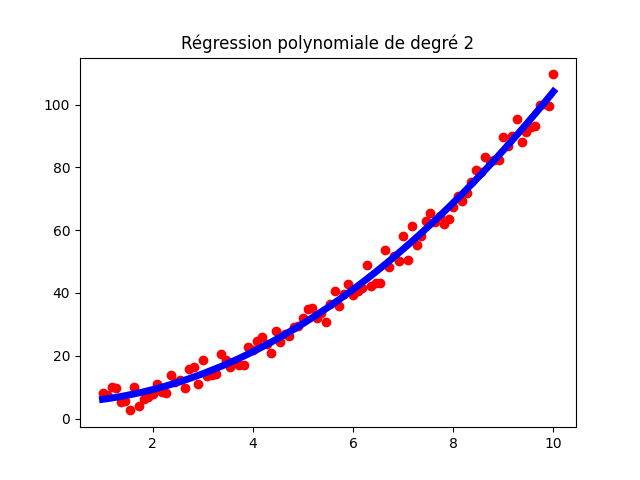
Par exemple si vous avez des données de forme polynomiale, vous pouvez d'abord appliquer une transformation polynomiale, puis appliquer une régression linéaire. Scikit-learn propose la notion de pipeline pour chainer des opérations. Voici un exemple de régression polynomiale.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
degre = 2
# création d'un ensemble X,Y clairement associé à une parabole
X = np.linspace(1, 10, 100) # création de 100 points en abscisse
Y = X**2 + 10*np.random.rand((100)) # création de 100 points en ordonnée
X = X.reshape((100, 1))
Y = Y.reshape((100, 1))
model = make_pipeline(PolynomialFeatures(degre), Ridge())
model.fit(X, Y)
Y_pred = model.predict(X)
# graphique du résultat
plt.scatter(X, Y, c="r")
plt.plot(X, Y_pred, c="b", lw=5)
plt.show()
Feature engineering▲
En analysant un dataset à multiples dimensions, vous serez rapidement confrontés à plusieurs problèmes :
- les modèles mettent trop de temps à s'exécuter ;
- il est moins aisé de se représenter l'importance de chaque variable et leurs liens.
Je vous invite à standardiser vos dimensions pour manipuler des données de même échelle et de même variance. Scikit-learn propose plusieurs outils de prétraitement comme le StandardScaler qui centre les données autour de la moyenne et divise le tout par la variance.
Tout d'abord, il sera nécessaire de nettoyer les dimensions (les features) de votre dataset pour mettre de côté celles qui semblent superflues ou inutiles (feature selection). Si malgré ça, il vous reste trop de dimensions, vous pourrez vous tourner vers les méthodes mathématiques pour réduire le nombre de features sans perdre trop d'informations : vous pourrez fusionner des colonnes à sémantique similaire, vous pourrez créer une nouvelle colonne qui reprend les données de plusieurs autres.
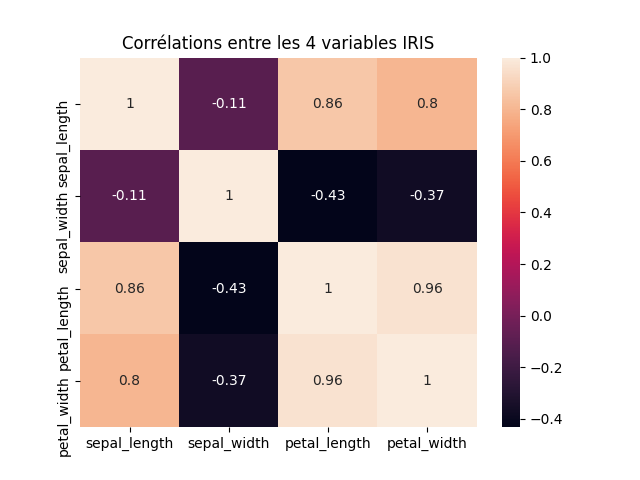
Au début d'une analyse de données, il est très intéressant de visualiser les corrélations entre toutes les features, cela permet de repérer d'un coup les colonnes qui évoluent ensemble et ça pourra guider votre analyse.
Vous pouvez visualiser ça sous la forme d'une heatmap (les valeurs proches de 1 ou de -1 indiquent des corrélations fortes).
La bibliothèque Seaborn propose le graphique de type pairplot, pour représenter très visuellement les liens entre les variables. Les couleurs représentent les différentes targets. La diagonale représente la distribution des targets suivant la caractéristique sélectionnée.
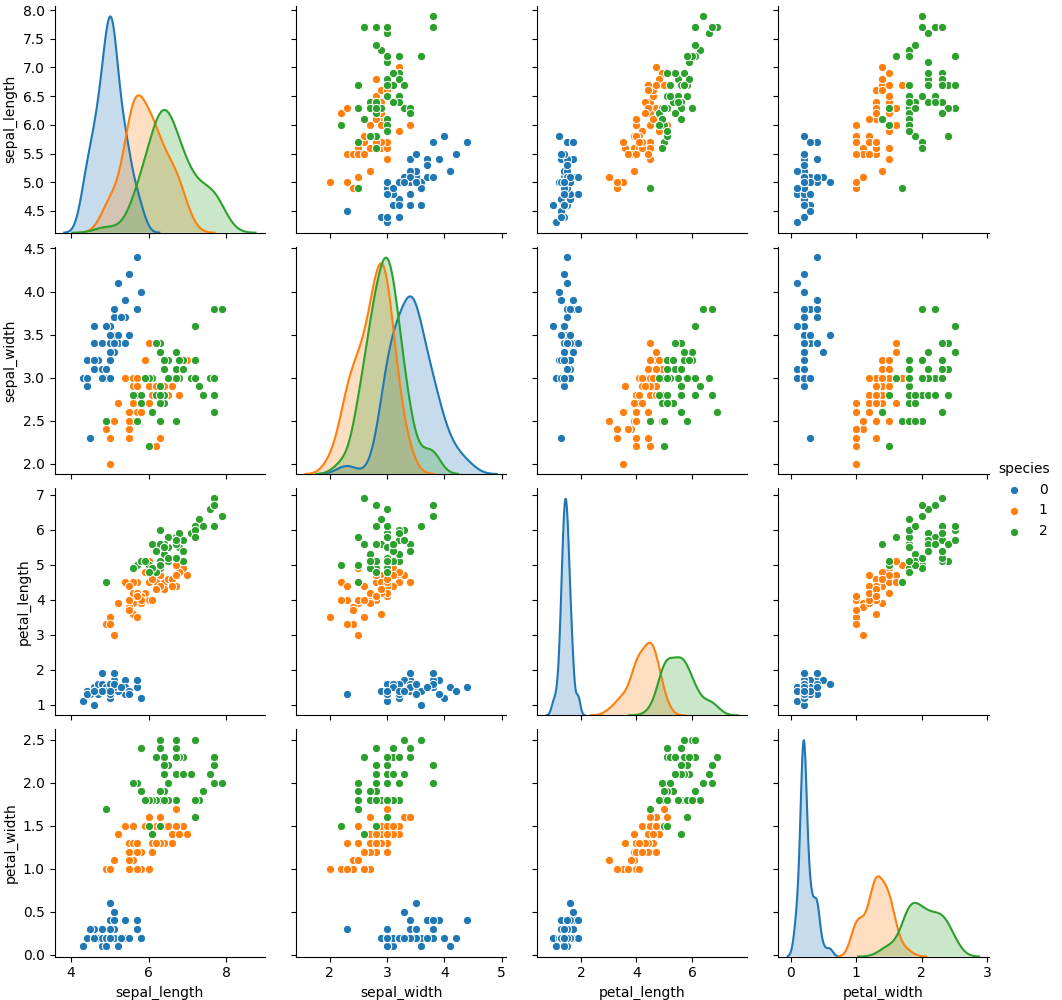
Ces deux graphiques permettent de repérer un lien très fort entre la largeur et la longueur des pétales. Nous repérons aussi qu'une des targets (la bleue notée 0) se détache des autres variétés, elle sera plus simple à prédire. Les deux autres variétés sont davantage enchevêtrées, mais nous avons vu qu'un classificateur simple en venait à bout.
Les caractéristiques de largeur et longueur de pétales semblent évoluer de manière très similaire, on pourra essayer d'en ignorer une en considérant que l'autre n'apporte pas d'information supplémentaire. C'est un moyen simple pour réduire la complexité du problème.
Une autre approche est celle de l'analyse en composante principale (principal component analysis - PCA). L'idée de cette technique est de repérer les principales “directions” que prend votre dataset (une fois qu'il a été centré et normalisé) pour le réexprimer suivant ces directions. En considérant les principales “directions”, il sera possible de réduire le nombre de dimensions du dataset sans perdre trop d'informations. Algébriquement, cela consiste à chercher les plus grandes valeurs propres du dataset et à le réexprimer dans la base des vecteurs propres associés, en ne prenant que les n premiers. On estimera que les petites valeurs propres définissent des “directions” n'amenant que peu d'informations, et pouvant donc être ignorées pour le bien de l'analyse.
La PCA n'a pas de “prédiction” à faire, elle transforme le dataset en un autre dataset, exprimé différemment. Une fois que votre analyse est faite, vous devrez réexprimer votre dataset dans les dimensions d'origine, c'est le rôle de la méthode inverse_transform(X_r). Sachez cependant que la transformation inverse ne pourra pas recréer l'information qui aura été perdue dans la réduction de dimensionnalité, vous ne retrouverez donc pas exactement les données de départ.
2.
3.
4.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_r = pca.fit(X).transform(X)
Nous pouvons appliquer une PCA sur le dataset IRIS (en quatre dimensions), elle nous permettra de pouvoir le représenter sur un graphique 2D.
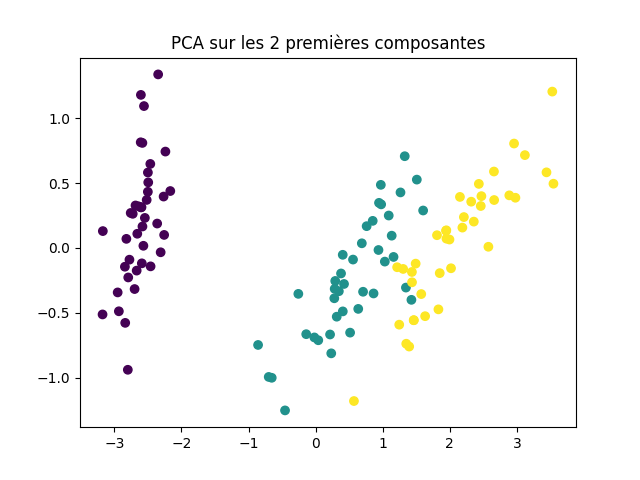
En réduisant le dataset aux deux principales composantes, nous constatons qu'il est quasiment séparable en trois clusters. Ça sera d'autant plus simple pour les classificateurs et nous avons moins de données à manipuler !
Clustering▲
Scikit-learn implémente de nombreux algorithmes de partitionnement de données. Ils permettent de regrouper les données similaires en l'absence de supervision (les données manipulées ne contiennent que des X, ils n'ont pas de Y).
Le partitionnement de données (ou apprentissage non supervisé) permet de regrouper les données qui se ressemblent et de leur associer un libellé commun. Il existe plusieurs algorithmes de partitionnement, certains permettent d'isoler le bruit du dataset, d'autres permettent de trouver le meilleur nombre de clusters à repérer.
Vous avez accès aux principaux algorithmes :
- k-means (voir mon article sur le sujet) ;
- DBSCAN (voir mon article sur le sujet) ;
- partitionnement spectral (voir mon article sur le sujet) ;
- partitionnement hiérarchique (voir mon article sur le sujet).
Comme à son habitude Scikit-learn propose une méthode fit(X), bien qu'ici la méthode intéressante soit fit_predict(X) qui renvoie les Y sous la forme d'un label deviné par l'algorithme.
En conclusion▲
Scikit-learn est un outil central dans l'utilisation du machine learning en Python. Tous les algorithmes les plus utilisés y sont présents. De plus cette bibiothèque s'utilise conjointement avec les autres bibliothèques Python : Numpy, Pandas (pour la manipulation des tableaux et de séries), Matplotlib (pour la visualisation) et Seaborn (pour la visualisation un peu plus évoluée).
De plus, la similarité des syntaxes permet de facilement comparer plusieurs modèles pour affiner les prédictions et trouver le meilleur modèle. C'est très appréciable.
La documentation très accessible incite à explorer les différents hyper-paramètres de chaque modèle, même si rapidement vous devrez étudier les aspects théoriques de chaque modèle pour aller plus loin.